
TrueInsight
Siemens/Altair Channel Partner
Menu



Sentiment Analysis with Altair RapidMiner
In this post we dive into how a user can perform a sentiment analysis using Altair RapidMiner. Perfect for marketing teams or quality assurance.
Altair RapidMiner has many applications when it comes to data acquisition, cleaning, preparation, and model generation. This can be applied to classification, regression, and other forms of predictive modeling. One such application many users might not be aware of in this tool is the ability to create a sentiment analysis model. This is a supervised learning model that can predict the emotional tone of a block of text based on historical data. This can be helpful for marketers to identify how customers feel about certain products, allowing companies to take the appropriate action in real time to ensure customer satisfaction.
To demonstrate this process in RapidMiner, we will stick to one of my favorite applications: Lego. We will begin by generating a collection of reviews for a given Lego set along with the star rating of the item. In this case, the star ratings can range from one to five, with one being the lowest or worst rating and five being the highest or best rating. Generally, marketers might already have this data in some structured format, but we will assume we have a collection of ratings and reviews in one long document; this document does not separate individual reviews, and it does not separate the individual pieces of data in each review (the reviewer, how long ago it was reviewed, the start rating, and the review itself).
We can start to prepare this dataset by first breaking each review into its own data point. After some inspection, we can identify that each review ends with a line “Reviewed on [Website],” where [Website] can be replaced by the website on which the review was made, such as Lego’s own site, or another distributor of the item. We can use RapidMiner’s built-in operator “Split Document into Collection” after reading the entire dataset, demonstrated in Figure 2. We can then set the split string to “Reviewed on” which will split the initial document into several documents along the breakpoints identified by the split string. In other words, we now have all of our reviews split into individual documents.
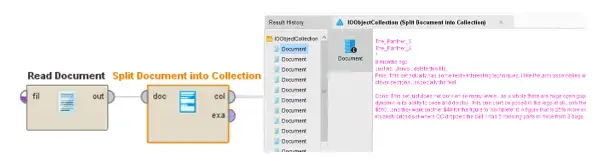
Fig 1. Splitting the original document into individual reviews.
From there, we need to extract the useful information from each document to generate attributes for each example. For RapidMiner, we can think of examples as rows of a spreadsheet and attributes as columns; each example is a data point, which can have one or more attributes describing some characteristic of that data point. This also requires some knowledge of the initial data set, but after some inspection, we quickly notice that each document is structured in a similar way. First, we see that the star rating is on the fourth line of each document. Next, we notice that each document states “n Months ago” or “n Years ago,” where n is an integer, and the whole text string represents how long ago the review was created. The text content of the review always begins immediately after this piece of information, so we extract all the text from each document after this line to generate the review content. Both of these are highlighted in Figure 2 below.
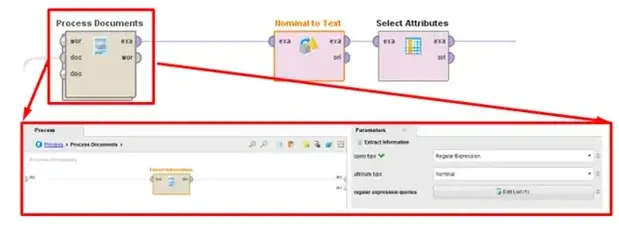
Fig 2. Key attributes of each review that we wish to extract.
We can accomplish the task of extracting the star rating and the review content from each document by using the “Extract Information” operator within the “Process Documents” operator. The outer operator here will allow us to define some set of instructions to perform on each of the documents in the collection (remember: a document in this example houses all of the information related to a single review/rating). We can then use string matching or regular expressions to define regions in each document that should be extracted as its own attribute. Figure 3 shows the “Process Documents” subprocess that allows us to do this.
Fig 3. Processing documents to extract attributes and prepare data set.
Once we have our data in a structured format, where each row (or example) stores the star rating and review text (our two attributes), we can begin to build and train a sentiment analysis model. We will need to generate a new attribute that can be used as the label for the sentiment of the review content. To do this, we will use the “Generate Attribute” operator that considers the star rating of the example; if the rating is 4 or 5, we consider the sentiment to be “Positive,” if it is 1 or 2, we consider the sentiment to be “Negative,” and a rating of 3 will result in a sentiment of “Indifferent.” We then set the new attribute “Sentiment” as the label of our data, convert the nominal attribute values to text, and filter out any examples with a Sentiment of “Indifferent.” That last step is not always necessary, but we only want to identify positive or negative sentiments in this example. Figures 4 and 5 show these operators in RapidMiner and the resultant training data.
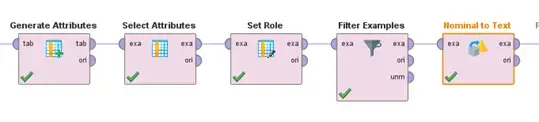
Fig 4. Operators to prepare and label training data.
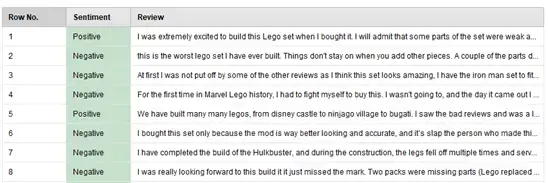
Fig 5. Table of resultant training data with “Sentiment” and “Review” attributes.
Now we will need to process the documents again, but we want to process the review text from each example this time. For each review, we will want to Tokenize the document (split it into a sequence of tokens, which will be connected strings of letters), use Transform Case to convert it into all lower case (for ease of comparison), and Filter Stopwords (English words that do not add value, such as “and” or “the”). This subprocess is shown in Figure 6 below.
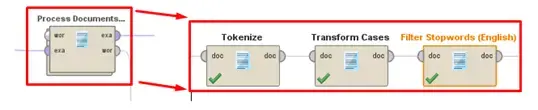
Fig 6. Subprocess to tokenize and transform the “Review” attribute in preparation for training.
To conclude the process of training the model, we implement cross validation. This includes two subprocesses: training and testing. For the training portion, we use a Support Vector Machine (SVM), to generate a model to predict sentiments based on the tokenized review content. RapidMiner allows you to customize many aspects of the SVM, including the kernel type, max iterations, loss function parameters, and others, but we will keep everything as the default for this example. The second half of cross validation is testing the model during training. To do this, we apply the model to the current training data and analyze the performance based on the accuracy of the sentiment predictions. We can see this operator block and the operators therein in Figure 9 below. The “Cross Validation” operator is very powerful because it allows you to customize and optimize a given learning model with much more ease than traditional approaches.
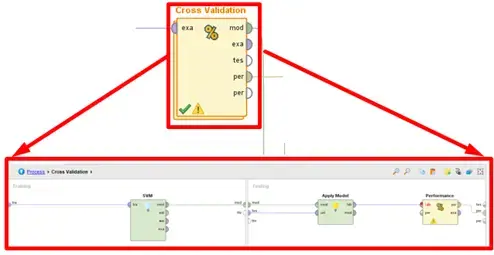
Fig 7. Implementation of Cross Validation to effectively train the sentiment analysis model.
Finally, we apply our model to an example that was not included in the training data. This will act as a more realistic test of how “good” our model turned out. We can quickly test this by creating a new document containing a review in RapidMiner, processing it the same way as the training reviews, combining the list of available tokens or words, and applying the trained model.
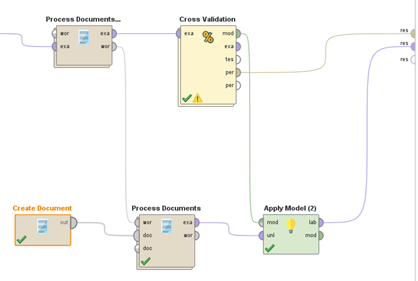
Fig 8. Connection of training model and applying to new example input.
I tried this with a new one-star review and a new five-star review, and I was able to successfully predict the negative and positive sentiments, respectively, which means our model seems to be behaving as desired! Figure 9 shows the predicted sentiment (with confidence levels) of the one-star review, which was assumed to have a negative sentiment as a true label.

Fig 9. Correctly predicted negative sentiment of one-star review.
This was a relatively straightforward example of sentiment detection in Altair RapidMiner, but it shows just the beginning of what is possible within the software. With a larger set of training data and more testing data, perhaps Lego can use a similar approach to gauge how customers feel about certain Lego sets and make adjustments as needed. If this process (or any data analysis process) interests you, please be sure to check back here and subscribe to our YouTube channel for more walkthroughs, tips, and demonstrations. As always, please do not hesitate to reach out to us with any specific questions or comments!